
The Gothic script used in codices Argenteus and Ambrosianus is encoded with more than 24 bits in Unicode/UTF-8. We say they are in the “Second half-pane”. Almost everything else of merit gets encoded with less than 24 bits, so software makers sometimes implements UTF-8 only up to 24 bits and hope that language minorities, who want to use characters above the limit, will be imprisoned for hate speech before reaching their office.
For LaTeX, I have tested only with XeTeX and TextEdit on Mac. We will use the fontspec library. We will also need a Wulfilan typeface as *.otf or *.ttf. We can place a copy in the catalogue where we have the .tex-file.
Some options would be:
Skeirs: http://www.robert-pfeffer.net/schriftarten/englisch/ by Robert Pfeffer
NotoSans Gothic: https://www.google.com/get/noto/#sans-goth by Steve Matteson
When saving the .tex-file, see to it that UTF-8 is selected in the dialog-box, as in the image.
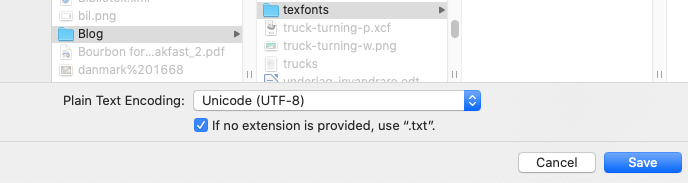
How to save a UTF-8 file from TextEdit on Mac.
Once we have loaded fontspec, the command:
\fontspec{〈file name〉}
.. can be used for testing. It simply switches to the font specified by file name. A simple testing example is due:
\documentclass[10pt]{article}
\usepackage{fontspec}
\begin{document}
\fontspec{Skeirs II.ttf}
𐌲𐌰𐌼𐌴𐌻𐌰𐌼 𐌷𐌴𐍂 𐌼𐌹𐌸 𐍃𐌺𐌴𐌹𐍂𐍃 ·𐌱· \\[0.7cm]
\fontspec{Silubr.otf}
𐍃𐍅𐌴𐌸𐍉 𐌲𐌰𐍃𐌰𐌹𐍈𐌰 𐍃𐌹𐌻𐌿𐌱𐍂·𐍉𐍄𐍆 \\[0.7cm]
\fontspec{NotoSansGothic-Regular.ttf}
𐌾𐌰𐌷 𐌽𐍉𐍄𐍉 𐍃𐌰𐌽𐍃 𐌲𐍉𐌸𐌹𐌺 · 𐍂𐌿𐌽𐍉𐌲𐌰𐍄𐌰𐍃𐍃 𐍃𐌼𐌹𐌸𐍉𐌳𐌰 𐍆𐌰𐌿𐍂 𐌲𐍉𐍉𐌲𐌻𐌰𐌹
\end{document}

For more serious usage, we will probably write mostly Latin in a document and would like a way to switch to Gothic and then back again.
\newfontfamily\nameOfCommand[〈options〉]{nameOfTypeFace}
After this command, suppose you chose ‘goth’ as name for the command, Wulfilan can be written in a span by means of:
{\goth 𐌸·𐌹· 𐌸𐌿 𐍅𐌰𐌻𐌰𐌹𐌸 𐌽𐌰𐌼𐍉𐌽}
For the options, I’d only suggest Scale=0.9 to make the Gothic text feel similar in size to the Latin.
As we are almost into programming with this matter, it could be a good idea to mention that in a language like Java, a Wulfilan character doesn’t fit into a char. So, for example:
char wulfK = (char) 0x1033A;
… will fail miserably. The crude solution is to use:
char[] wulfK = Character.toChars(0x1033A);
A Gothic word thus becomes a 2-dimensional matrix of char variables, each pair of which holds a UTF-16-encoding of a character. These can easily be converted to UTF-8 Strings and StringBuffers, or written to file.
Unicode Consortium have a code chart for Wulfilan here or accessible from the charts page.